MySQL笔记¶
| 参考视频课程(YouTube) |
mysql的语句关键词是 大小写不敏感的 。
mysql语句以分号作为一句话的结束,所以根据个人习惯,可以将一行语句分成多行书写。
1.Database的创建与删除¶
创建一个database
选中某个database
删除database
设置database只读
当数据库被设置成只读时,数据库不能修改和删除。
2.创建表¶
在数据库中创建一个表
如:
CREATE TABLE employees (
employee_id INT,
first_name VARCHAR(50),
last_name VARCHAR(50),
hourly_pay DECIMAL(5 , 2),
hire_date DATE
);
其中VARCHAR(50)中的数字50代表这个字符串最大长度50。DECIMAL(5,2)中的第一个数字5代表最大值,2代表小数点后位数。
重命名table
删除table
在table中添加列
修改table中的列标题
修改列的数据类型
移动列的顺序
将列1移动到列2的右侧。将某列移动到首列
删除某列
3.插入数据(在表中插入行)¶
插入一行数据
在括号中写入一行中每列的内容。注意每列的数据格式,输入值要和数据格式对应,每列之间用 逗号 隔开。如:
一次插入多行
仅插入部分数据(部分列)
上述语句仅插入表的columnName1和columnName2列的数据。
Warning
只要没有插入完整的各列数据,都需要指定插入的数据是哪几列的。
4.查看数据¶
选定/查看table的所有列
选定/查看table的特定列
列名不是必须按照表中的左右的,可以交换查看特定行
实际上=是一个操作符,会返回为true的行,所以可以这样写。
5.更改与删除行¶
更改某行的某列
上述语句将表tablename中列columnname2的值为value2的行的columnName列数据更改为value。
Note
如果使用上述语句更改行的某列的值出现以下报错:
You are using safe update mode and you tried to update a table without a WHERE that uses a KEY column.
是因为当前指定的WHERE column的column不是索引键key column
解决方法:
使用如下命令将列设置为索引键或者主键
-- 添加索引
ALTER TABLE employees ADD INDEX (employee_id);
-- 设置为主键
ALTER TABLE employees ADD PRIMARY KEY (employee_id);
如果要改变某特定行的多列值,可以这样写:
将某一行的某一列的值设置为空
将整列设置为某个值
删除表中的某行
删除表中所有数据(慎用)
6.自动保存、保存与回滚¶
在MySQL中,默认开启自动保存。也就是说你每次做的任何更改都会自动保存。
关闭或开启自动保存
手动保存
回滚
在自动保存关闭的状态下,如果出现错误更改,我们可以归滚到上一次保存。
7.获取日期、时间、日期及时间¶
MySQL中有内置函数获取这些数据。
我们可以创建如下表来测试。
CREATE TABLE test(
myDate DATE,
myTime TIME,
date_time DATETIME
);
-- 插入
INSERT INTO test
VALUES (
CURRENT_DATE(), CURRENT_TIME(), NOW()
);
SELECT * FROM test;
其中可以对CURRENT_DATE()加1或者减1以获取明天或者昨天的日期。
8.表列数据限制¶
在Mysql中,可以对表的数据做一些限制,如某列下的数据不能相同,如uid。或者必须有值
UNIQUE限制
Info
UNIQUE其实是UNIQUE KEY的简写
UNIQUE限制保证这一列下的数据不能相同,添加限制有两种方法。一是在创建表时限制
如果已经创建了表,可以通过以下语句添加限制条件。
NOT NULL限制
NOT NULL可以限制某列数据必须不为空,当尝试插入数据时,若该列为空,则会报错。
-- 在创建时加限制
CREATE TABLE <tableName>(
column1 <dataType> NOT NULL,
column2 <dataType>
);
-- 对现有表加限制
ALTER TABLE <tableName>
MODIFY COLUMN <columnName> <dataType> NOT NULL;
自定义限制CHEKC
除了上述限制,我们还可以自定义限制,如限制某一列的数据必须是大于或在某个区间内的数。这样的限制可以使用CKECK实现。
-- 在创建表时添加限制
CREATE TABLE <tableName>(
column1 <dataType>,
column2 <dataType>,
...
columnN <dataType>,
CHECK (column1 >= 50)
);
建议给限制条件命名,这样方便改动表格时删除限制条件。
-- 在创建表时添加限制
CREATE TABLE <tableName>(
column1 <dataType>,
column2 <dataType>,
...
columnN <dataType>,
CONSTRAINT <nameOfCheck> CHECK (column1 >= 50)
);
对已经创建的表,可以通过如下命令添加限制条件。
删除表中的某个限制条件
9.列的默认值¶
对于有些写入操作,比如我们想在写入时自动记录时间,可以使用DEFAULT实现。
在创建表时添加DEFALUT
对现有表加DEFAULT
Warning
使用DEFAULT属性后,插入值时若不想手动指定值,即让表使用设置的默认值,需要指定插入数据属于哪几行,也就是使用指定行的插入方式。
10.主键¶
主键 也是约束的一种,主键等同于 NOT NULL 加 UNIQUE ,但是一张表只能有一个主键。
创建表时指定主键
CREATE TABLE <tabName>(
column1 <dataType> PRIMARY KEY,
column2 <dataType>,
...
columnN <dataType>
);
对现有表加主键
11.功能与属性¶
自增(AUTO_INCREMENT)
仅能对被设置成**KEY**的列设置自增属性,且一个表只能有一个有自增属性的列,被设置为自增属性的列在插入时若不指定值,则会从表的最后个值开始自增。
若表为空,则默认从1开始。但可以手动修改开始的值。
同时也可以在插入时指定值。
在创建表时设置自增属性
CREATE TABLE <tabName> (
-- 一般将主键作为自增的,数据类型只能为INT或BIGINT,如uid
column1 <dataType> PRIMARY KEY AUTO_INCREMENT,
...
column <dataType>
);
对现有表加自增属性
更改自增的下一个值
Warning
如果设置的值比表最后一行的值小,下一个自增值会是表最后一行的下一个值。
12.FOREIGN KEY¶
FOREIGN KEY的作用是标记当前列是与外部(另一个表)相关联的,主要用于以下这类场景:
- 订单管理中订单表与客户表通过客户id管理
在创建表时创建FOREIGN KEY
CREATE TABLE <tabName> (
column <dataType>,
FOREIGN KEY (column) REFERENCES <anotherTab>(column2)
);
对现有表加FOREIGN KEY
ALTER TABLE <tabName>
ADD CONSTRAINT <foreignKeyName>
FOREIGN KEY (<columnIntabName>) REFERENCES <anotherTable>(<anotherColumn>);
Warning
如果在表1中有指向表2某列的FOREIGN KEY,那么sql会自动限制删除表2在表1FOREIGN KEY中出现的值的行。
FOREIGN KEY是一种跨表约束
删除 :
13.JOIN¶
JOIN功能可以通过FOREIGN KEY以某种关系展示两个表的内容。分为LEFT JOIN、INNER JOIN、RIGHT JOIN。具体使用可以看作如下Venn图。
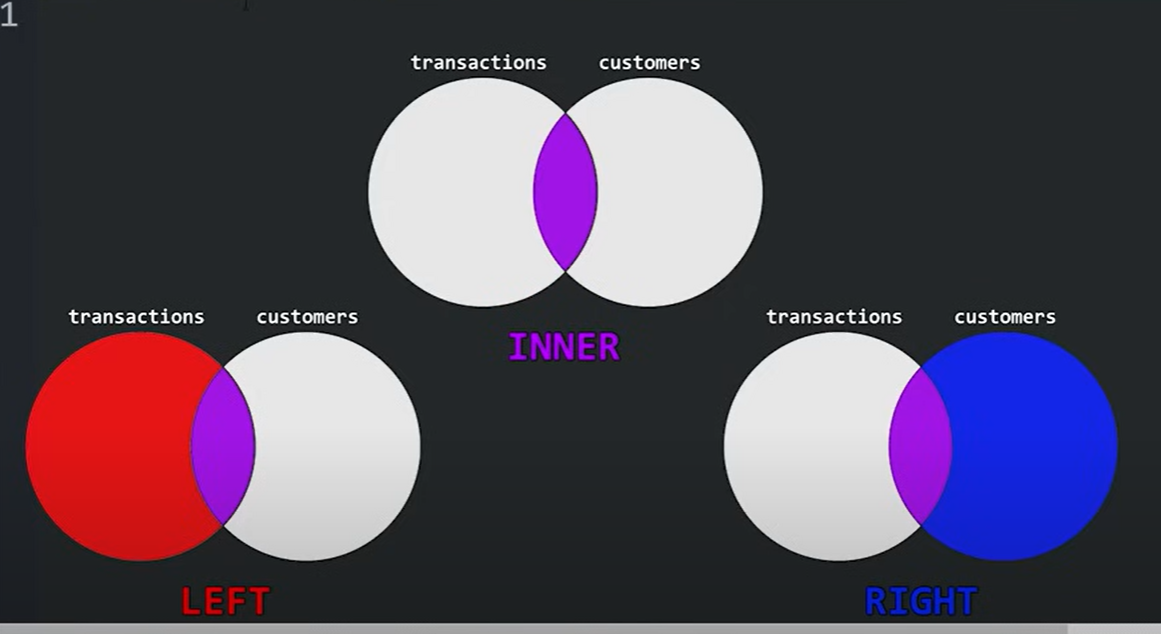
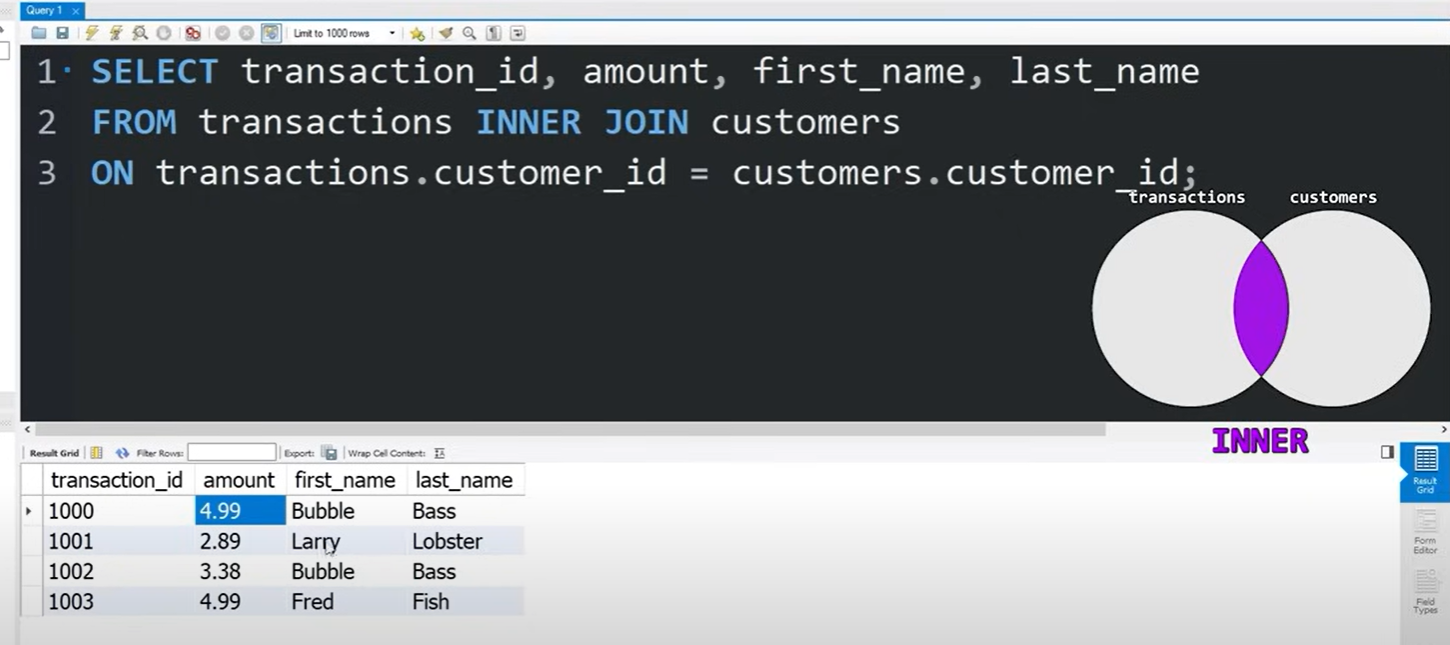
INNER JOIN展示了两个表中都有的数据,此处的有是指都有的FOREIGN KEY。LEFT JOIN会展示左表中所有的数据以及左表中的FOREIGN KEY对应的右表数据。RIGHT JOIN则会展示右表即右表中有的FOREIGN KEY数据对应的左表数据。
语句中<tab1>.<col1>和<tab2>.<col2>是两个表中的FOREIGN KEY的列。
如果只想获取部分数据,可以将*改成具体列名,列名可以是两个表中的。
将INNER JOIN换成LEFT JOIN、RIGHT JOIN就是对应的效果。
14.函数¶
Mysql中有许多内置函数,下面简要介绍如下内置函数的一些使用方法:
- COUNT
- MAX
- MIN
- AVG
- CONCAT
COUNT¶
COUNT可以计算表中某列共有多少行数据。
SELECT COUNT(<colName>)
FROM <tabName>;
-- 输出列默认名是 COUNT(<colName>)
-- 可以给输出的列起别名(alias),下同
SELECT COUNT(<colName>) AS <alias>
FROM <tabName>
MAX¶
MAX可以找到列中的最大值。
MIN¶
MIN可以找到列中的最小值
AVG¶
顾名思义,显示列的平均值。
代码略
CONCAT¶
CONCAT可以实现将多个字符串拼接显示。如某张表里有first_name和last_name,可以用如下的方式拼接。
15.通用匹配符号¶
在MySQL中,有两个通用匹配符号,分别是%代表多个不确定字符、_代表单个不确定字符。
要使用通用匹配符号查找数据,不能使用=,而要使用LIKE。
示例:
16.排序¶
使用SELECT输出数据时还可以进行排序。使用ORDER BY进行排序。
ASC 代表升序,这是默认的,可以不写。 DESC 表示降序。上述示例排序了两个列,当第一列相同时按照第二列排序。
17.查看部分¶
使用LIMIT可以仅查看数据中的部分,如前10条、第10到20条,这在分页显示时很有用。
SELECT * FROM <tabName>
LIMIT <n>;
-- 显示表中前n条数据
SELECT * FROM <tabName>
LIMIT <offset>, <n>;
-- 显示从开始往后offset个数据以后的n条数据
-- 如 LIMIT 10, 10 表示显示第11到20
此外,LIMIT还可以结合ORDER BY使用,如
18.显示多个表的内容¶
使用UNION可以将多张表的SELECT结果合并。
示例如下:
Warning
注意,使用UNION合并的结果必须具有相同的列数。且列标题会按照UNION前的显示。
当UNION合并的两结果存在相同数据的行时,默认只显示其中一个,可以使用UNION ALL显示重复的所有数据。
19.高级用法:JOIN自身¶
当一个表有如下内容时,比如员工之间的等级制度,一个员工的上司是另一个员工时。通常使用员工id记录,为了显示员工的姓名和相应上司的姓名,我们可以JOIN表自身。
示例:
SELECT a.id, a.first_name, a.last_name,
CONCAT(b.first_name, " ", b.last_name)
FROM employees AS a
INNER JOIN employees AS b
ON b.id = a.supervisor;
上述SQL语句实现了通过表a中的上司id与表b的id对应的行,展示员工id、员工姓名、员工上司姓名。
Info
注意,在对表自身JOIN时,必须使用AS给表一个别名,且列必须从以<别名>.<列>形式写,因为SQL无法从两个具有相同列名的相同表中区分你所想表达的要求。
20.逻辑表(VIEW)¶
与TABLE不同,VIEW也是一种表,但是VIEW不直接存储数据,而是通过某种逻辑从TABLE中获取数据,当TABLE中的数据变更时,VIEW中的数据也会同步变更。当然,在前述中能对TABLE进行的操作(修改除外)都能对VIEW执行。
如果将TABLE看作实际存储层,那么VIEW可以看作是逻辑层。
VIEW可以方便地实现与拓展api或完成其他功能。
VIEW的简单示例:
当然,可以进行更高级的应用,如JOIN、CONCAT等。
21.索引(INDEX)¶
索引会将列转化成一个二叉树,这样在搜索的时候会比其他列更快。不是索引的列相当于线性列表。当然,在索引加快搜索的同时,索引的插入会花更多的时间。
查看表中有的索引 :
会发现,UNIQUE和PRIMARY KEY也是索引。
创建索引:
创建索引时还可以同时创建多列的索引,如:
索引的搜索和正常的搜索、查看操作是一样的。
22.嵌套查询(SUBQUEIRES)¶
SELECT返回的结果可以嵌套在另一个SELECT中,称之为嵌套查询。SELECT返回的结果可以看作是一个集合,也可以看作是一个变量。这取决于具体的查询结果。
下面是几个嵌套查询的示例
SELECT first_name, last_name, hourlyPaid, (SELECT AVG(hourlyPaid) FROM employees) AS avgPaid
FROM employess;
SELECT first_name, last_name, hourlyPaid
FROM employees
WHERE hourlyPaid > (SELECT AVG(hourlyPaid) FROM employess);
SELECT first_name, last_name
FROM customs
WHERE cumstomId IN
(SELECT customId FROM transactions WHERE customId IS NOT NULL);
23.数据聚合(GROUP BY)¶
GROUP BY可以实现数据聚合功能,如同将相同发件人的邮件聚合在一起一样。
比如一个商店记录了若干天的顾客购买明细,现在想要查看每天一共收入是多少,就可以使用聚合功能。
示例如下:
Info
这里可以理解为GROUP BY处理表格数据,然后输出一个表格,但是GROUP BY在一个语句中只能出现一次,如果相应实现多次分组聚合,可以使用嵌套查询。
不同于一般的SELECT查询语句,GROUP BY的结果只能用HAVING筛选,而不是WHERE。
HAVING语句只能处理聚合后的数据,而WHERE只能处理聚合前的数据。
下面是一个相对复杂的运用,既有WHERE又有HAVING。
SELECT store, SUM(amount) AS total_sales
FROM sales
WHERE sale_date >= '2025-05-01' -- 先筛选出5月后的记录
GROUP BY store -- 按商店分组
HAVING total_sales >= 200; -- 再筛选销售总额>=200的商店
GROUP BY还有一个拓展语法:GROUP BY ... WITH ROLLUP;。这条语句可以将非GROUP BY的行再次聚合(相加),可以用在如下场景:
比如某超市要计算一周中每天的销售额,同时又需要这一周总的销售额,这时可以这样写
24.ON DELETE¶
前文可知,当删除FOREIGN KEY时,会报错。但是我们可以在创建时使用ON DELETE功能实现删除某个FOREIGN KEY对应外表数据时对含有FOREIGN KEY的数据做一些处理。
ON DELETE SET NULL¶
当删除FOEIGN KEY的对应数据时,会将表中含有这个FOREIGN KEY的行的FOREIGN KEY设置为NULL。
ON DELETE CASCADE¶
在删除FOREIGN KEY对应数据时,删除使用这个FOREIGN KEY的整行数据。
ON DELETE的创建¶
只能在创建表的时候创建,如:
CREATE TABEL <tabName> (
col1 <dataType>,
FOREIGN KEY(col1) REFERENCES <anotherTable>(col2)
ON DELETE SET NULL
);
如果相对现有表添加ON DELETE功能,则需要先删除FOREIGN KEY的CONSTRAINT。
现有表添加ON DELETE
ALTER TABLE <tabName>
ADD CONSTRAINT <constraint_name>
FOREIGN KEY(col1) REFERENCES <anotherTable>(col2)
ON DELETE SET NULL;
25.函数(PROCEDURE)¶
MySQL中可以将一段或几段sql语句保存成一个函数(或者叫过程)。
PROCEDURE的创建:
DELIMITER $$ -- 更改语句结束符号为 $$ 这是为了防止创建时将内部语句的分号识别为结束,最后还要改回来
CREATE PROCEDURE <function_name>(IN <para1> <dataType>, IN <para2> <dataType>, ...)
BEGIN
<sql_sentence> -- 这里的语句要以;分号结束
END $$
DEMINITER ;
调用:
26.触发器 TRIGGER¶
TRIGGER可以在执行UPDATE、INSERT、DELETE执行前后做一些自动化处理。
具体写法:
DELIMITER $$
CREATE TRIGGER <name>
BEFORE UPDATE ON <tabName>
FOR EACH ROW
BEGIN
...
END $$
DELIMITER ;
Info
创建语句中的BEFORE关键词还可以是AFTER,用来表示在操作前或者操作后,这十分重要。
在TRIGGER语句中还有两个特殊变量:NEW和OLD,NEW表示操作后的值,比如插入时要插入的值,OLD表示操作前的值。注意,在AFTER中,是无法修改NEW数据的。
此外,如果TRIGGER中仅有一条MySQL语句,可以不用写BEGIN ... END。在写BEGIN ... END的时候,要注意修改终止符。
几个视频课程中的示例:
CREATE TRIGGER before_hourly_pay_update
BEFORE UPDATE ON employees
FOR EACH ROW
SET NEW.salary = (NEW.hourly_pay * 2080);
CREATE TRIGGER after_salary_delete
AFTER DELETE ON employees
FOR EARH ROW
UPDATE expenses
SET expense_total = expense_total - OLD.salary
WHERE expense_name = "salaries";
索引/键 总结¶
MySQL中的KEY其实就是索引。
MySQL中有以下类型的键。
| 类型 | 关键字 | 特点 |
|---|---|---|
| 主键 | PRIMARY KEY | 唯一且非空,表里只能有一个 |
| 唯一键 | UNIQUE KEY | 唯一,可以有多个 |
| 普通键(一般索引) | KEY / INDEX | 不要求唯一,主要加速查询 |
| 外键 | FOREIGN KEY | 建立表与表之间的关系,保证数据的一致性和完整性 |
在创建表时添加KEY
对现有表加KEY
ALTER TABLE <tabName>
ADD KEY (<columnName>);
-- 也可以给索引起名
ALTER TABLE <tabName>
ADD KEY <indexName> (<columnName>);
Warning
索引名是给数据库优化内部执行速度用的,所有增减删改操作都应该使用列名。
ADD CONSTRAINT的相关说明¶
添加constraint的语句书写完整形式如下
ADD CONSTRAINT <constaintName>这一行可以全部省略,也可以只不写命名
sql中的保留符号¶
| 名称 | 符号 |
|---|---|
| 空 | NULL |
sql中的比较操作符¶
| 名称 | 符号 |
|---|---|
| 等于 | = |
| 大于 | > |
| 小于 | < |
| 不等于 | != |
逻辑运算符¶
| 关键词 | 名称 | 示例 |
|---|---|---|
| AND | 与 | <condition1> AND <condition2> |
| OR | 或 | <condition1> OR <condition2> |
| NOT | 非 | NOT <condition> |
| BETWEEN | 在两者中间 | <col> BETWEEN <value1> AND <value2> |
| IN | 在某个集合中 | <col> IN ("value1", "2", "3", ...) |
其他注意事项¶
- sql中判断是否是空只能用
IS